Detection of Large Language Model Usage in Austrian News Media Through Linguistic Markers
2Affiliation withheld by request
Abstract
Background: The increasing adoption of Large Language Models (LLMs) in journalism raises questions about editorial transparency and the extent of automated content generation in news media.
Objective: This study develops and applies a methodology to detect LLM-generated content in Austrian online news publications by analyzing characteristic punctuation patterns, specifically the usage of em-dashes and en-dashes.
Methods: We collected and analyzed articles from seven major Austrian news outlets (OE24, Exxpress, Heute, Krone, Falter, Kurier, Kleine Zeitung) spanning October 2021-2025. The analysis examined temporal patterns in dash usage, distinguishing between CMS (Content Management System) updates and actual LLM deployment through differential analysis of space-hyphen-space vs. space-dash-space patterns.
Results: Three publications (Exxpress, OE24, Heute) showed clear evidence of widespread LLM usage for content generation, particularly in listicle and entertainment categories. Two publications (Kurier, Kleine Zeitung) demonstrated selective LLM adoption in specific content categories. Two publications (Krone, Falter) showed no evidence of LLM-based content generation beyond potential editorial assistance.
Conclusions: Linguistic marker analysis provides a scalable, language-independent method for detecting LLM-generated journalism. The findings reveal significant variation in LLM adoption across Austrian media outlets, with particular concentration in lifestyle and entertainment content categories.
Keywords: Large Language Models, Journalism, Content Detection, Austrian Media, Em-dash, Automated Writing
1. Introduction
1.1 Background
The rapid advancement of Large Language Models (LLMs) such as ChatGPT (released November 2022) has fundamentally altered the landscape of automated content generation. While LLMs offer potential benefits for journalistic workflows—including research assistance, fact-checking, and editorial support—their use for primary content generation raises significant questions about editorial standards, transparency, and journalistic integrity.
In Austria, the integration of AI technologies into journalism has been facilitated through public funding mechanisms, notably the RTR (Austrian Regulatory Authority for Broadcasting and Telecommunications) Digital Transformation Fund. Several major news organizations received substantial grants for AI-related projects, including Mediengruppe Österreich (parent company of OE24), which received €287,000 in 2024 for "AI image recognition, database correction, and content creation."
1.2 The Challenge of Detection
Detecting LLM-generated content poses unique challenges. While several sophisticated detection methods exist, they often require access to model outputs or training data, computationally intensive analysis, language-specific training datasets, and cooperation from publishers (which is rarely forthcoming).
This study proposes a simpler, more accessible approach based on observable linguistic patterns that emerge consistently across LLM-generated text.
1.3 The Em-dash Phenomenon
LLMs exhibit a characteristic tendency to insert em-dashes (—) and en-dashes (–) into generated text, particularly in English and German. This behavior appears to stem from training data composition, stylistic modeling, and structural patterns where LLMs use dashes to create parenthetical expressions and emphasis.

Figure 1: ChatGPT-generated article in English showing 7 em-dashes, demonstrating the characteristic punctuation pattern of LLM-generated text.

Figure 2: ChatGPT-generated article in German showing 13 en-dashes, illustrating how LLMs insert dashes even in German-language text where traditional journalism uses them sparingly.
In German journalism, traditional editorial style typically favors en-dashes (–) for ranges and connections, hyphens (-) for compound words, and sparse use of em-dashes, which are more characteristic of English-language writing. The sudden increase in em-dash and en-dash usage in German-language journalism thus serves as a potential marker for LLM involvement.
1.4 Research Questions
This study addresses the following questions:
- Can temporal analysis of punctuation patterns reliably distinguish between human-written and LLM-generated journalistic content?
- How can we differentiate between CMS updates (which auto-format dashes) and actual LLM usage?
- Which Austrian news outlets have adopted LLMs for content generation, and in which content categories?
- What is the timeline of LLM adoption in Austrian journalism relative to the public release of ChatGPT?
1.5 State of the Art
Work on detecting language-model generated text spans several families of approaches. Supervised detectors train classifiers on labeled human vs. LLM text to identify distributional differences; however, recent studies have shown such detectors are brittle and can be defeated by paraphrasing, prompt adjustments, or adversarial finetuning [3, 4]. Signal-based methods rely on perplexity or token-level irregularities as proxies for modelness (e.g., transformer detectors and perplexity-based heuristics), but they are sensitive to domain shift and editing by humans [2]. Watermarking has been proposed by model providers as a prospective solution, yet is not widely deployed in production models and can be disrupted by minor rewriting.
In parallel, the journalism and media studies literature surveys the opportunities and risks of automated journalism: newsroom integration, productivity gains, shifting roles, and profound ethical questions around transparency, accountability, and audience trust [6, 10–12]. Much of this work argues for disclosure norms and editorial oversight when AI systems contribute to content creation.
Finally, stylometry and authorship attribution offer a complementary, interpretable lens. Rather than black-box detection, stylometry leverages human-understandable features—sentence and word statistics, function word profiles, and punctuation behaviors—to reason about authorship and stylistic shifts [13–17]. Our approach sits in this line of work: instead of predicting “AI vs. human” directly, we measure linguistic markers (e.g., space–en dash–space, quotation mark forms) over time and across categories, and use differential analysis to disambiguate CMS typographic changes from LLM-generated content. This makes the method language-agnostic, auditable, and resistant to trivial evasion through minor paraphrasing.
2. Methodology
2.1 Data Collection
2.1.1 Publication Selection
We selected seven major Austrian news publications representing different market segments: OE24 (oe24.at), Exxpress (exxpress.at), Heute (heute.at), Krone (krone.at), Falter (falter.at), Kurier (kurier.at), and Kleine Zeitung (kleinezeitung.at). Additionally, Die Tagespresse (satirical news) was analyzed as a control.
2.1.2 Article Acquisition
Articles were obtained through sitemap harvesting. Publications maintain XML sitemaps for search engine indexing, organized by publication date.

Figure 3: Sitemap XML structure showing monthly article indices (example: OE24). Note: These sitemaps were subsequently restricted after data collection began.

Figure 4: Example of sitemap file becoming empty/restricted during the investigation.

Figure 5: Example JSON structure of scraped article data (October 2021 articles) showing URL, title, and content fields.
The temporal scope covered October articles from years 2021-2025 (Falter: 2019-2025), totaling 123,455 articles across all publications and years. Articles were stored locally for analysis but not redistributed due to copyright considerations.
| Publication | 2019 | 2020 | 2021 | 2022 | 2023 | 2024 | 2025 | Total |
|---|---|---|---|---|---|---|---|---|
| Exxpress | - | - | 1,474 | 1,220 | 1,246 | 752 | 1,007 | 5,699 |
| Falter | 550 | 381 | 381 | 377 | 340 | 350 | 399 | 2,778 |
| Heute | - | - | 3,877 | 4,030 | 3,029 | 4,316 | 6,270 | 21,522 |
| Kleine Zeitung | - | - | 2,637 | 2,903 | 2,906 | 5,269 | 7,774 | 21,489 |
| Krone | - | - | 7,285 | 7,114 | 6,987 | 6,909 | 7,617 | 35,912 |
| Kurier | - | - | 4,362 | 5,452 | 4,310 | 3,190 | 3,513 | 20,827 |
| OE24 | - | - | 2,728 | 2,873 | 2,982 | 3,195 | 4,260 | 16,038 |
| Die Tagespresse* | - | - | 34 | 39 | 37 | 36 | 44 | 190 |
| Total | 550 | 381 | 22,778 | 23,008 | 21,837 | 24,017 | 30,884 | 123,455 |
*Satirical news outlet included as control
Notable patterns in article volume: Heute showed a 62% increase 2024→2025 (4,316→6,270 articles), Kleine Zeitung 48% (5,269→7,774), and OE24 33% (3,195→4,260). These volume increases in 2025 coincide with observed stylistic shifts, potentially indicating increased reliance on automated content generation to maintain higher publication rates.
2.1.3 Temporal Window Selection
The analysis period (2021-2025) was carefully chosen to capture both baseline behavior and the adoption trajectory of LLM technology in Austrian journalism. The window begins with October 2021 and 2022, establishing baseline patterns before ChatGPT's public release in November 2022. This pre-release period is critical for distinguishing normal editorial variation from AI-induced changes. The years 2023 and 2024 capture the early adoption period, when organizations would have been piloting AI technologies, likely funded by the RTR grants received during this time. Finally, 2025 represents the mature adoption phase, where pilot projects transitioned to production deployment.
Focusing exclusively on October articles for each year served multiple purposes: it controlled for seasonal variation in editorial content and publishing patterns, ensured comparable sampling across years, and made the analysis computationally feasible given the massive scope of data. The consistency of patterns observed within this single month across multiple years suggests that seasonal effects are minimal compared to the structural changes induced by LLM adoption.
2.2 Linguistic Marker Analysis
We measured three distinct patterns: (1) space-en-dash-space ( – ), the target pattern indicating potential LLM usage; (2) space-hyphen-space ( - ), the traditional manual typing pattern; and (3) raw hyphen count for baseline comparison. Measurements were normalized as dashes per article and dashes per 1,000 characters.
Articles were categorized by dash frequency into five groups: 0 dashes (none), 1-3 dashes (minimal), 4-7 dashes (moderate, typical for LLM-generated content), 8-12 dashes (high), and 13+ dashes (very high).
2.3 Confound Control: CMS Updates
Modern Content Management Systems can automatically convert - to – as typographic enhancement. To distinguish CMS updates from LLM adoption, we tracked both patterns simultaneously. A CMS update shows inverse correlation (one decreases as the other increases proportionally), while LLM adoption shows independence (en-dashes increase while hyphens remain stable).
2.4 Stylometric Feature Set and Normalization
Beyond dash patterns, we apply a stylometric battery to each article: sentence-level (average/max sentence length; subordinate clause ratio), word-level (type-token ratio, stopword ratio, average word length), and punctuation (en-dash, em-dash, comma, semicolon, quotes and typographic quotes, ellipses, exclamation and question marks). All features are normalized per 1,000 tokens. Categories are included only if they exist in all five years. We compute per-feature, per-category effect sizes as standard-deviation–normalized mean shifts between pre-2025 and 2025, yielding interpretable magnitudes that can be ranked and aggregated.
2.5 Dual-Track Quotation Analysis (CMS vs. LLM)
We track straight quotes (") and typographic quotes („”) separately. A purely typographic CMS upgrade tends to replace straight quotes with typographic ones with the overall quotation density staying roughly constant. LLM-generated articles, in contrast, often introduce additional quotation or quasi-quotation boilerplate, increasing total quotation density. As a negative control, semicolons are monitored to capture author idiosyncrasy rather than process change, underscoring the need to combine multiple stylometric signals.
2.6 Cross-Publication Aggregation and Workflow
Per-feature effects are summarized at the category level (for persistent categories) and then aggregated to publication-level profiles. Workflow: (1) collect articles via sitemaps; (2) normalize and extract features; (3) apply differential tests for CMS vs. LLM; (4) compute z-scored mean shifts (pre-2025 vs 2025) per category; (5) aggregate to publication-level summaries and visualize.
3. Results
3.1 Initial Evidence: The Commander Riker Screenshot
The investigation was triggered by a social media post by user @plocaploca (Commander Riker) on Bluesky showing an OE24 article containing unedited ChatGPT artifacts. The screenshot captured tell-tale phrases and formatting patterns characteristic of ChatGPT output, providing preliminary evidence that at least one major Austrian outlet was using LLMs in production without adequate editorial oversight to remove the generated markers.

Figure 6: Screenshot showing ChatGPT-specific text patterns in published OE24 article, providing direct evidence of LLM usage.
This preliminary evidence confirmed that at least one major Austrian outlet was using LLMs in production. The question became: how widespread is this practice, and can we detect it systematically across multiple publications and over time?
3.2 Data Collection Infrastructure
Articles were obtained via sitemap harvesting, a technique that exploits the XML sitemaps that news organizations maintain for search engine optimization. These sitemaps provide structured access to article URLs organized by publication date, making systematic data collection feasible.
Figure 7: Sitemap XML structure showing monthly article indices (example: OE24). Note: These sitemaps were subsequently restricted after data collection began.
Interestingly, midway through the investigation, OE24's historical sitemaps became inaccessible - an intriguing coincidence given the timing of the research. However, by that point, the necessary data had already been collected.
Figure 8: Example JSON structure of scraped article data (October 2021 articles) showing URL, title, and content fields.
Each article was stored as a JSON object containing the URL, title, publication date, category classification, and full text content. This structured format enabled efficient batch processing and linguistic analysis across the entire corpus of 123,455 articles.
3.2 Aggregate-Level Analysis
3.2.1 OE24 (Mediengruppe Österreich)

Figure 7: OE24 dash usage distribution 2021-2025. From 2021-2024, 83-85% of articles had no/few dashes (green/yellow). In 2025, this drops to ~62% while medium/high intensity articles (orange/red) surge dramatically.
Key Finding: OE24 shows dramatic shift in 2025, coinciding with completion of €287,000 RTR-funded "KI Bilderkennung/Datenbanken/Korrektur/Creation" project.

Table 2: RTR funding for Mediengruppe Österreich (OE24's parent company), showing €287,528 in 2024 for "KI Bilderkennung/Datenbanken/Korrektur/Creation" among other AI-related projects.
3.2.2 Exxpress

Figure 8: Exxpress dash usage 2021-2025. Stable patterns 2021-2024 (~53-57% None, ~37-40% Low). 2025 shows dramatic break: None drops to ~25%, Medium rises to ~25%, High to ~8%, Very High to ~2%.
Key Finding: Exxpress shows the most dramatic shift of all publications.

Table 3: Förderungen for eXXpress Medien showing infrastructure projects 2022-2023, though no explicitly labeled AI content generation projects.
3.2.3 Heute

Figure 9: Heute dash usage 2021-2025. Very stable 2021-2023 (~89-93% None, ~7-10% Low). 2024 shows first shift: None to ~48%, Low to ~40%, Medium ~10%. 2025 continues: None ~40%, Low ~47%, Medium ~11%, High ~2%.
Key Finding: Heute was an early adopter, with changes visible already in 2024, consistent with €140,876 RTR funding for "KI-gestützter Journalismus" in 2024.

Table 4: RTR funding for Heute (AHVV Verlags GmbH) 2022-2025, including €140,876 in 2024 for "KI-gestützter Journalismus" among 16 total projects.
3.2.4 Krone and Falter

Figure 10: Krone dash usage 2019-2025. Stable 2019-2022 (~89-92% None). 2023 shift begins: None to ~50%, Low to ~43%. Pattern stabilizes through 2025.

Figure 11: Falter dash usage 2021-2025 showing similar shift pattern to Krone.
Key Finding: Both show pattern changes, but differential analysis (below) reveals these are due to CMS updates, not LLM usage.
3.3 Differential Analysis: CMS vs. LLM
3.3.1 CMS Update Pattern (Falter)

Figure 12: Falter en-dash vs hyphen usage 2019-2025. Blue line (en-dashes): rises from ~0.02 (2019) to explosive ~0.50 (2023). Green line (hyphens): stable ~0.22-0.29 (2019-2022), then drastic drop to nearly 0 from 2023. The dramatic crossing 2022-2023 marks CMS conversion event.
Interpretation: Inverse correlation indicates automatic CMS conversion, not LLM adoption.
3.3.2 CMS Update Pattern (Krone)

Figure 13: Krone showing similar CMS conversion pattern between 2023-2024.
3.3.3 LLM Usage Pattern (OE24)

Figure 14: OE24 en-dash vs hyphen 2021-2025. Blue (en-dashes): starts ~0.68, drops to ~0.41 (2024), then dramatic jump to ~1.35 (2025) – nearly tripling. Green (hyphens): practically flat at nearly 0 throughout. This pattern indicates NEW dash-heavy content = LLM usage.
3.3.4 LLM Usage Pattern (Heute)

Figure 15: Heute showing en-dash explosion in 2025 while hyphens remain stable – parallel increase indicates LLM usage.
3.3.5 LLM Usage Pattern (Kurier)

Figure 16: Kurier showing mixed pattern - some CMS conversion visible, but 2025 spike suggests LLM adoption in specific categories.
3.4 Extended Stylometric Analysis
Beyond dash counting, comprehensive stylometric analysis examined multiple linguistic features.
3.4.1 Additional Punctuation Markers

Figure 17: ChatGPT output showing typographically "fancy" quotation marks („"), another characteristic marker of LLM-generated text.

Figure 18: Regular quotation marks (") usage per 1,000 tokens in OE24 across categories, 2021-2025.

Figure 19: "Fancy" quotation marks („") usage per 1,000 tokens in OE24, showing dramatic increase in typographically correct German quotation marks.

Figure 20: Exxpress "Gänsefüßchen" (fancy quotes) per 1,000 tokens. Standard quotes nearly absent, suggesting direct replacement with LLM output.

Figure 21: Falter quotation marks (") per 1,000 tokens: stable ~18 per thousand in 2021-2022.

Figure 22: Falter "fancy" quotes transition to ~10 per thousand from 2023 (matching the other ~10 from closing quotes), totaling original ~18-20 - indicating CMS typographic upgrade, not LLM.
Key Finding: Falter's quotation pattern shows replacement (total quote frequency stays constant), while OE24/Exxpress show addition (new quotes appear), supporting CMS vs. LLM distinction.
See Methods (Section 2.5) for details on the dual-track quotation analysis that distinguishes CMS replacement from LLM addition.
3.4.2 Multi-Feature Stylometric Analysis

Figure 23: En-dash frequency per 1,000 tokens across OE24 categories, showing clear 2025 spike in multiple categories.
A comprehensive stylometric battery examined sentence-level features (average/max sentence length, subordinate clause ratios), word-level features (type-token ratio, stopword usage, average word length), and punctuation features (en-dash, em-dash, comma, semicolon, quotes, ellipses, exclamation/question marks) — all normalized per 1,000 tokens. For comparability, categories were analyzed only if they existed in all five years under study, and mean-shift scores were computed as standard-deviation-normalized differences between pre-2025 and 2025 distributions. This yields an interpretable effect size per feature and category, allowing us to rank shifts and separate genuine editorial change from random year-to-year noise.
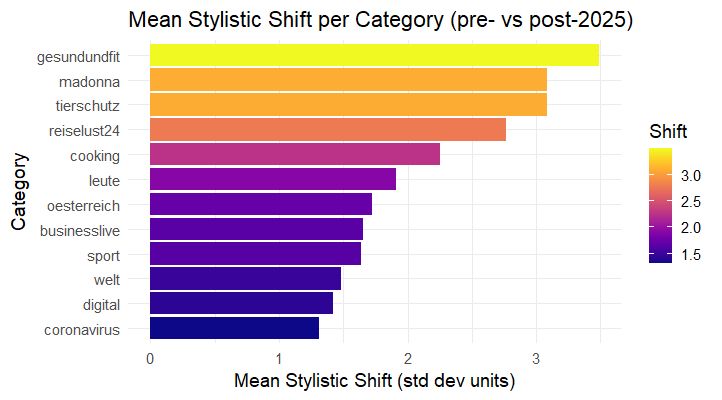
Figure 24: Mean shift per category (pre-2025 vs post-2025) across multiple stylometric features. Categories ranked by magnitude of change.

Figure 25: Change in stylometric features for top 3 OE24 categories (Gesundundfit, Tierschutz, Madonna), showing comprehensive shift across multiple dimensions.
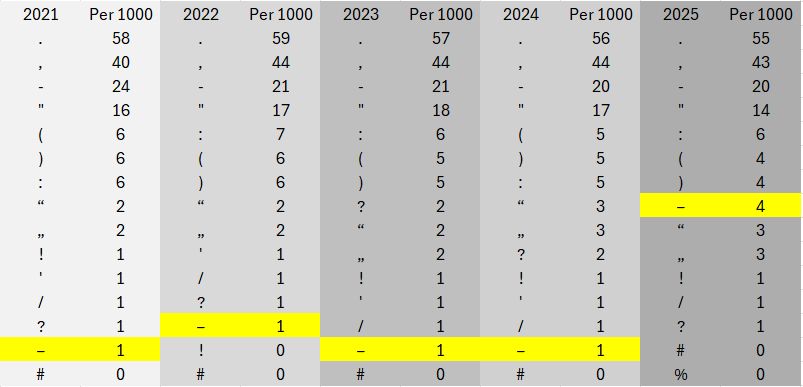
Figure 26: En-dash usage showing clear pre-2025 vs post-2025 distinction across categories.
Key Finding: The "Österreich" (Austria news) category shows minimal change across all features (suggesting human authorship continues), while lifestyle categories show largest shifts across multiple dimensions. In contrast, high-velocity verticals such as Shopping, Gesund&fit, and Madonna show multi-feature shifts well above 1 standard deviation, consistent with templated generation and heavier reuse of punctuation-rich constructions (dashes, quotations). The simultaneous movement of dashes, quotations, and sentence-level statistics argues for a process change (LLM insertion) rather than a mere style tweak.
3.4.3 Cross-Publication Stylometric Comparison

Figure 27: Mean stylistic shift (in standard deviation units) between 2025 and earlier years, for all categories existing across all 5 years. Allows direct comparison across publications.
Cross-publication perspective: the standardized mean-shift chart shows the largest overall stylistic displacements for Exxpress, followed by OE24 and Heute. Krone and Falter exhibit the smallest composite shifts, which aligns with the CMS-conversion story established in Section 3.3 — typography improved, but style in the broader sense remained stable. Kurier and Kleine Zeitung sit in the middle: noticeable changes concentrated in leisure and lifestyle categories, but not a wholesale transformation of the editorial profile.
3.5 Category-Level Analysis
3.5.1 Heute Categories

Figure 28: Heute top 6 categories: Klimaschutz (+3.96), Life (+2.21), Wien (+2.02), Tiere, Community (+1.62), Unterhaltung (+1.18).

Figure 29: Heute additional categories showing Österreich (+1.16), Sport (+1.05), Nachrichten (+0.89) with moderate increases, while Startseite (+0.32) and Wetter (+0.12) show minimal change.
Heute appears to have introduced LLM support first in lower-risk, high-throughput desks (Klimaschutz/Life/Wien), with modest spillover into general news. The semicolon analysis (Figure 31) serves as a negative control, reinforcing the value of combining multiple stylometric families.

Figure 30: Heute en-dash frequency per 1,000 tokens normalized across categories, showing clear 2025 differentiation.
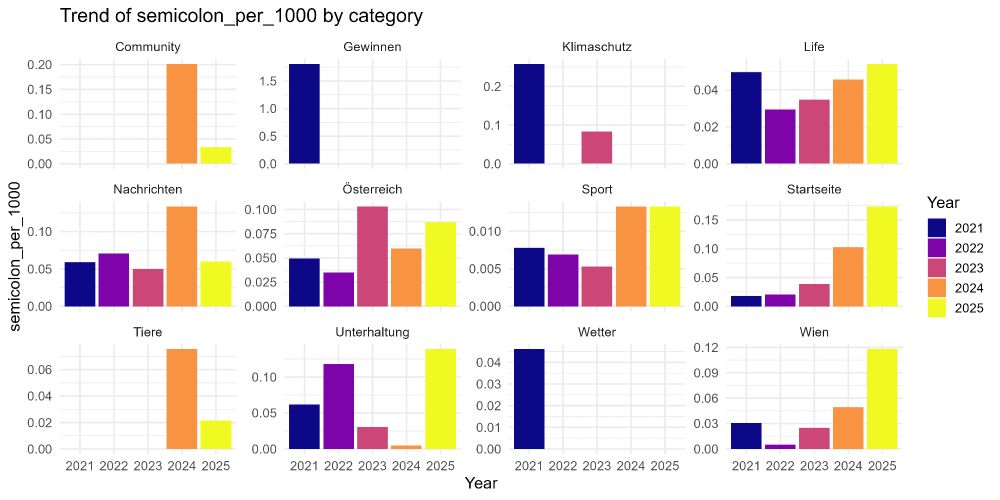
Figure 31: Heute semicolon frequency per 1,000 tokens - less clear pattern, potentially individual author preferences (e.g., Wien author favoring semicolons).
3.5.2 OE24 Categories

Figure 32: OE24 top 3 categories: Shopping (+10.60), Tierschutz (+7.90), Reiselust24 (+4.22) showing dramatic increases in 2025.

Figure 33: OE24 additional categories: Madonna (+3.79), Gesundundfit (+2.76), Buzz24 (+2.19), Cooking (+2.00), Leute (+1.97), Digital (+1.43).
The magnitude and consistency of shifts within lifestyle verticals argue for semi-automated, template-like generation. The joint displacement of dashes, quotes, and sentence metrics suggests outputs are primarily generated and then lightly standardized by the CMS pipeline.
3.5.3 Exxpress Categories

Figure 34: Exxpress categories: Politik (+2.80), Economy (+1.80), Lifestyle (+1.35), Meinung (+0.97), Sport (+0.89). Notable: even news/politics show significant increases.

Figure 35: Exxpress en-dash per 1,000 tokens, showing dramatic increase across all categories in 2025.
Exxpress exhibits the most pervasive transformation. Even Politik and Wirtschaft display sizable shifts, which is unusual for outlets that keep “hard news” manual. Despite taxonomy inconsistencies, the cross-feature movement points to broad LLM usage rather than isolated desk experiments.
3.5.4 Kurier and Kleine Zeitung

Figure 36: Kurier en-dash usage per 1,000 tokens across categories.

Figure 37: Kleine Zeitung en-dash per 1,000 tokens across categories.
Interpretation: Kurier and Kleine Zeitung reflect selective adoption: measurable changes in leisure and entertainment strands while core news desks remain relatively stable. This aligns with a risk-managed rollout: automate low-stakes formats first (guides, lists, evergreen). Their volume surge in 2025 (Table 1) likely reflects throughput gains from these automated tracks.
3.6 Funding Context
Table: RTR funding for Mediengruppe Österreich (parent company of OE24), showing €287,528 in 2024 for "KI Bilderkennung/Datenbanken/Korrektur/Creation" project.
Table: RTR funding for Heute (AHVV Verlags GmbH), including €140,876 in 2024 for "KI-gestützter Journalismus".
Additional AI-related funding identified:
- Die Presse: €26,000 for "Artificial Intelligence @ Die Presse"
- Kleine Zeitung: €12,000 for "Truly - der AI-basierte Fact-Checker"
- Kurier: €70,000 for "KI-Services"
- Exxpress: Multiple infrastructure projects 2022-2023, no explicitly labeled AI projects
3.7 Summary Classification
Confirmed LLM Usage for Content Generation:
- Exxpress: Pervasive across all categories
- OE24: Concentrated in lifestyle/entertainment categories
- Heute: Moderate usage, early adopter
Selective/Limited LLM Usage:
- Kurier: Specific categories (Freizeit, Stars, Leben)
- Kleine Zeitung: Specific categories (Leute, Lebensart)
No Evidence of LLM Content Generation:
- Krone: Pattern explained by CMS update
- Falter: Pattern explained by CMS update
4. Discussion
4.1 Methodological Contributions
This study demonstrates that simple linguistic markers can provide robust detection of LLM-generated journalism when combined with temporal analysis, differential analysis, category-level granularity, and multi-feature validation. The methodology is valuable because it requires no special access, is language-independent, is computationally simple, and is robust to evasion.
4.2 Funding and Adoption Timeline
The correlation between RTR funding and LLM deployment is striking. Larger grants correspond to more pervasive LLM usage, suggesting that public funding facilitated the transition from pilot projects to production deployment.
4.3 Content Strategy: The Listicle Pattern
A consistent pattern emerges: LLM deployment is concentrated in "listicle" and lifestyle content (shopping guides, top 10 lists, health/wellness, entertainment, travel, pet care), while traditional news categories largely maintain human authorship. This suggests a strategic choice: low-stakes content → LLM generation acceptable; high-stakes content → human authorship maintained.
4.4 The CMS Confound: A Methodological Lesson
The differential analysis proved essential. Without examining both dash patterns, we would have incorrectly classified Krone and Falter as using LLMs. This highlights that technical infrastructure changes must be distinguished from content generation changes.
4.5 Implications for Journalism
The findings raise concerns about editorial transparency (none of the publications disclose LLM usage to readers), labor displacement (LLMs displacing writers in specific content verticals), quality differentiation (two-tier system emerging), and public funding concerns (Austrian taxpayers funded implementations without transparency requirements).
4.6 Implications for Journalism
The findings raise several concerns:
Editorial Transparency: None of the publications disclose LLM usage to readers. While some funding applications mention "AI-supported journalism," actual articles carry no indication of automated generation.
Fact-Checking Failures: The Exxpress misinformation example (Section 3.8) demonstrates that LLM deployment without adequate editorial oversight enables publication of factually incorrect content.
Labor Displacement: The concentration in lifestyle/listicle content suggests LLMs are displacing writers in specific content verticals, potentially affecting journalism employment.
Quality Differentiation: The pattern suggests a two-tier system emerging: human-written "serious" news vs. LLM-generated "lifestyle" content.
Public Funding Concerns: Austrian taxpayers funded these AI implementations through RTR grants, yet receive no transparency about which content is human vs. machine-generated.
4.7 Comparison to Prior Work
This study differs from most LLM detection research in several ways:
- Real-world deployment: Examines actual published journalism, not experimental datasets
- Multi-year temporal analysis: Tracks adoption over time rather than single-point detection
- Granular categorization: Identifies where LLMs are deployed, not just whether they're used
- Public accountability focus: Centers transparency and public funding, not just technical detection
The stylometric approach complements more sophisticated ML-based detectors by providing interpretable, auditable evidence that can support public accountability claims.
5. Limitations
5.1 Methodological Limitations
Single-month sampling: Analysis focused on October articles for computational feasibility. Seasonal variations or month-specific editorial decisions could affect patterns, though the year-over-year consistency within October samples suggests this is minimal.
Sitemap availability: Data collection relies on sitemaps remaining accessible. During the investigation, OE24's historical sitemaps were restricted, though data had already been collected.
Language specificity: While the en-dash pattern appears robust across languages, this study examined only German-language publications. Cross-linguistic validation is needed.
Category classification: Publications use different category taxonomies, making direct cross-publication category comparisons challenging.
5.2 Detection Limitations
False positives possible: A human writer who extensively uses en-dashes could theoretically produce similar patterns, though the sudden 2025 shift across multiple categories makes this unlikely as the sole explanation.
Selective editing: If LLM output is heavily edited by humans before publication, linguistic markers may be partially removed. However, the consistency of patterns suggests minimal post-generation editing.
Evolving models: As LLMs improve, characteristic markers may change. The en-dash pattern reflects current (2022-2025) model behavior and may not persist in future models.
Hybrid workflows: Cannot distinguish between full LLM generation vs. LLM-assisted writing (e.g., human writes outline, LLM expands). Both would show similar markers.
5.3 Scope Limitations
Seven publications: While representative of major Austrian media, many smaller outlets were not examined.
October-only: Full year analysis would provide more robust conclusions but was computationally prohibitive.
No print analysis: Online-only content examined; print editions may show different patterns.
Text-only: Images, videos, and multimedia content not analyzed.
6. Conclusions
This investigation demonstrates that simple linguistic markers, particularly en-dash frequency combined with differential analysis, can reliably detect LLM deployment in journalism when analyzed across temporal, categorical, and multi-feature dimensions.
Key findings:
- Three major Austrian publications (Exxpress, OE24, Heute) show clear evidence of systematic LLM usage for content generation
- Two publications (Kurier, Kleine Zeitung) show selective, category-specific LLM deployment
- Two publications (Krone, Falter) show no evidence of LLM content generation beyond potential editorial assistance
- LLM deployment concentrates in lifestyle, entertainment, and listicle categories, with traditional news largely remaining human-authored
- Public funding through RTR grants (€287k-€140k) correlates with deployment timeline
- No publications transparently disclose LLM usage to readers
- Evidence of factual errors in LLM-generated content raises quality concerns
Methodological contributions:
- Differential analysis technique for distinguishing CMS updates from LLM deployment
- Multi-feature stylometric validation approach
- Temporal granularity for tracking adoption timelines
- Category-level analysis for identifying selective deployment
Implications:
- For journalism: Need for transparency policies regarding AI usage
- For regulation: Public funding of AI journalism deployments should require disclosure
- For readers: Current inability to distinguish human from machine-generated content
- For research: Simple, interpretable markers can complement sophisticated ML detection
Future work:
- Expand to full-year analysis across multiple years
- Include additional Austrian and international publications
- Develop automated monitoring systems for tracking LLM deployment trends
- Investigate reader perceptions and preferences regarding AI journalism
- Examine correlation between LLM usage and engagement/quality metrics
The findings underscore the need for editorial transparency standards in an era where AI-generated journalism is increasingly common yet rarely disclosed.
Data and Code Availability
Due to copyright considerations, the scraped article data cannot be publicly redistributed. However:
- Extracted linguistic features (dash counts, quotation marks, sentence lengths, etc.) are available upon reasonable request to the corresponding author
- Category classifications and article metadata (excluding full text) are available upon request
- Analysis methodology is fully described in Section 2 and can be replicated using publicly accessible sitemaps
Interested researchers may contact the corresponding author at contact@mariozechner.at for feature datasets or methodological guidance.
Acknowledgments
We thank the Bluesky community for their engagement, feedback, and support throughout this investigation. Special thanks to Commander Riker (@plocaploca.bsky.social) for the initial observation that triggered this work.
We also acknowledge the decision-makers at Austrian media organizations who determined that deploying Large Language Models for journalism was a fantastic idea. Their choices made this research possible.
References
LLM Detection and Text Generation
- Antoun, W., Mouilleron, V., Sagot, B., & Seddah, D. (2023). Towards a robust detection of language model generated text: is ChatGPT that easy to detect? arXiv preprint arXiv:2306.05871.
- Mo, Y., Qin, H., Dong, Y., Zhu, Z., & Li, Z. (2024). Large language model (LLM) AI text generation detection based on transformer deep learning algorithm. arXiv preprint arXiv:2405.06652.
- Shi, Z., Wang, Y., Yin, F., Chen, X., Chang, K.W., & Hsieh, C.J. (2024). Red teaming language model detectors with language models. Transactions of the Association for Computational Linguistics, 12, 1-17.
- Nicks, C., Mitchell, E., Rafailov, R., Sharma, A., Finn, C., & Ermon, S. (2023). Language model detectors are easily optimized against. The Twelfth International Conference on Learning Representations.
- Shi, W., Ajith, A., Xia, M., Huang, Y., Liu, D., Blevins, T., Chen, D., & Zettlemoyer, L. (2023). Detecting pretraining data from large language models. arXiv preprint arXiv:2310.16789.
AI in Journalism
- Ali, W., & Hassoun, M. (2019). Artificial intelligence and automated journalism: Contemporary challenges and new opportunities. International Journal of Media, Journalism and Mass Communications, 5(1), 40-49.
- Rojas Torrijos, J.L. (2021). Semi-automated journalism: Reinforcing ethics to make the most of artificial intelligence for writing news. In News Media Innovation Reconsidered: Ethics and Values in a Creative Reconstruction of Journalism (pp. 149-164). Wiley.
- Zhaxylykbayeva, R., Burkitbayeva, A., Zhakhyp, B., & Turebekova, B. (2025). Artificial intelligence and journalistic ethics: A comparative analysis of AI-generated content and traditional journalism. Journalism and Media, 6(1), 45-62.
- Monti, M. (2019). Automated journalism and freedom of information: Ethical and juridical problems related to AI in the press field. Opinio Juris in Comparatione, 2(1), 1-22.
- Broussard, M., Diakopoulos, N., Guzman, A.L., Abebe, R., Dupagne, M., & Chuan, C.H. (2019). Artificial intelligence and journalism. Journalism & Mass Communication Quarterly, 96(3), 673-695.
- Gutiérrez-Caneda, B., García Lindén, C., & López-García, X. (2024). Ethics and journalistic challenges in the age of artificial intelligence: Talking with professionals and experts. Frontiers in Communication, 9, 1-14.
- Sonni, A.F., Hafied, H., Irwanto, I., & Latuheru, R. (2024). Digital newsroom transformation: A systematic review of the impact of artificial intelligence on journalistic practices, news narratives, and ethical challenges. Journalism and Media, 5(4), 1432-1449.
Stylometry and Authorship Attribution
- Calle-Martin, J., & Miranda-Garcia, A. (2012). Stylometry and authorship attribution: Introduction to the special issue. English Studies, 93(3), 251-258.
- Kumarage, T., & Liu, H. (2023). Neural authorship attribution: Stylometric analysis on large language models. 2023 International Conference on Cyber Security and Computer Science (ICONCS) (pp. 1-8). IEEE.
- Ramnial, H., Panchoo, S., & Pudaruth, S. (2015). Authorship attribution using stylometry and machine learning techniques. In Intelligent Systems Technologies and Applications (pp. 113-125). Springer.
- Sundararajan, K., & Woodard, D. (2018). What represents "style" in authorship attribution? Proceedings of the 27th International Conference on Computational Linguistics (pp. 2814-2822).
- Eder, M. (2011). Style-markers in authorship attribution: A cross-language study of the authorial fingerprint. Studies in Polish Linguistics, 6(1), 99-114.
Additional Sources
- OpenAI. (2022). ChatGPT: Optimizing language models for dialogue. https://openai.com/blog/chatgpt
- RTR (Austrian Regulatory Authority for Broadcasting and Telecommunications). (2024). Digitaler Transformationsfonds: Geförderte Projekte. https://www.rtr.at/